Simulando Ataques DDoS com IA (e ensinando uma IA a se defender)
| Categoria: experimentos
Simulando Ataques DDoS com IA (e ensinando uma IA a se defender)
Esse post é sobre um experimento que fiz como parte da minha Iniciação Científica no CESAR School. A ideia geral é: e se a gente usasse Inteligência Artificial tanto para simular ataques de rede quanto para treinar um sistema de defesa? E o mais interessante — e se os dois aprendessem um com o outro?
Vou tentar explicar de forma acessível o que foi feito, o que funcionou, o que não funcionou, e o que os resultados significam.
O contexto: minha IC
Estou desenvolvendo uma pesquisa chamada Arquitetura Adversarial Dual-GAM, que basicamente propõe criar dois modelos de IA em competição:
- Uma GAM Atacante, responsável por gerar tráfego de rede malicioso cada vez mais sofisticado
- Uma GAM Defensora, que aprende continuamente a identificar e bloquear esses ataques
O ciclo entre os dois simula o que acontece no mundo real: atacantes evoluem suas técnicas, sistemas de defesa precisam acompanhar. A questão central da pesquisa não é "detectar DDoS melhor" (isso já existe e funciona bem). A questão é: como criar uma defesa que se adapte a ataques que ela nunca viu antes?
DDoS (Distributed Denial of Service) é o tipo de ataque escolhido como domínio de validação, por ter datasets públicos bons e ser bem documentado na literatura.
O dataset
Usei o CIC-IDS2017, um dataset público da Universidade de New Brunswick muito citado na literatura de segurança. Especificamente o arquivo de sexta-feira, que contém tráfego benigno e ataques DDoS.
Ao todo foram 221.264 registros com 77 features de fluxo de rede — coisas como duração do fluxo, tamanho de pacotes, flags TCP, taxa de bytes por segundo, etc. A distribuição ficou em ~128k amostras de DDoS e ~93k de tráfego benigno.
Antes de qualquer modelo, fiz uma análise exploratória e plotei um PCA 2D dos dados:
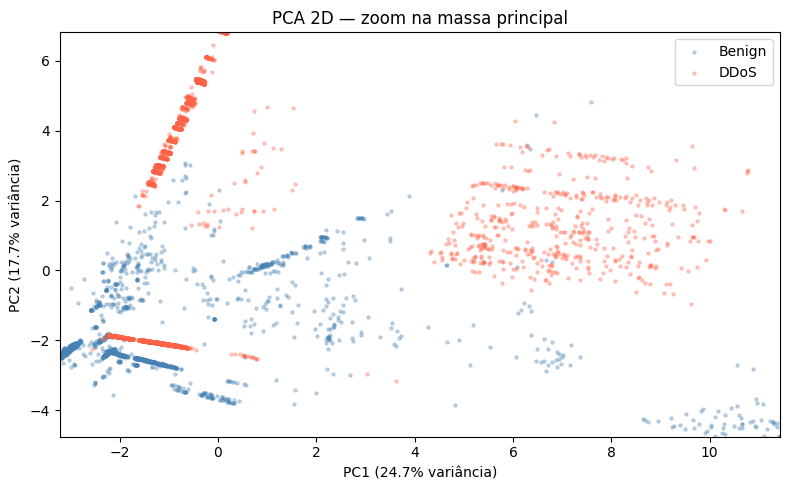
Esse gráfico já revelou algo importante: existe um cluster de DDoS completamente separado à direita (fácil de detectar), mas também uma região à esquerda onde DDoS e tráfego benigno se misturam mais. É nessa região difícil que o experimento fica interessante.
Passo 1: O Defensor Estático (baseline)
Antes de qualquer coisa adversarial, treinei um classificador simples — uma MLP (rede neural densa) com 3 camadas em PyTorch — para separar tráfego benigno de DDoS.
O resultado foi impressionante e, ao mesmo tempo, esperado:
- Acurácia: 99.91%
- Precision DDoS: 0.9996
- Recall DDoS: 0.9989
- F1: 0.9993
Praticamente perfeito. Isso confirma o que qualquer profissional de segurança diria: detectar DDoS volumétrico clássico é trivial para ML. O PCA já tinha antecipado isso — as classes são bem separáveis.
Esse modelo virou o baseline da pesquisa. O objetivo a partir daqui é mostrar que mesmo esse defensor "perfeito" pode ser enganado — e como ele aprende a se defender.
Passo 2: O Atacante — e os problemas que apareceram
Aqui começa a parte interessante.
A primeira abordagem foi treinar um gerador clássico: uma rede que recebe ruído aleatório e tenta produzir vetores de features que o defensor classifique como benigno. O resultado foi... tecnicamente 100% de evasão desde a primeira epoch.
Parece ótimo, mas era uma mentira. Ao investigar, ficou claro o problema: o gerador não aprendeu a imitar tráfego DDoS real e se disfarçar. Ele simplesmente aprendeu a gerar vetores em regiões do espaço que o defensor nunca tinha visto durante o treino — fora de qualquer distribuição real. A probabilidade média de uma amostra gerada ser classificada como DDoS era 0.000002. O defensor estava confiante demais que era benigno justamente porque não era nada parecido com nada real.
Esse é um problema clássico em GANs chamado mode collapse — o gerador encontra um atalho fácil em vez de aprender a distribuição real dos dados.
A segunda tentativa adicionou uma loss de realismo: além de enganar o defensor, o gerador precisava gerar amostras com média e desvio padrão próximos ao DDoS real. Melhorou a distribuição estatística, mas o problema de fundo persistiu — o defensor ainda via probabilidade ~0 de DDoS nas amostras geradas.
Passo 3: Perturbação Adversarial —o que funcionou
A virada veio com uma mudança de abordagem. Em vez de gerar tráfego do zero a partir de ruído, o atacante passou a partir de amostras reais de DDoS e aprender perturbações pequenas que enganam o defensor.
A ideia: pega um pacote DDoS real, aplica uma perturbação controlada aprendida pela rede, e tenta fazer o defensor achar que é tráfego benigno. É um ataque muito mais realista — o tráfego ainda se parece com DDoS, só foi sutilmente modificado para escapar da detecção.
Com isso, o ciclo adversarial finalmente funcionou como esperado.
Os resultados do ciclo
Rodei 20 rodadas de co-evolução. Em cada rodada: o atacante tenta evadir, o defensor retreina com as novas amostras, medimos os dois.
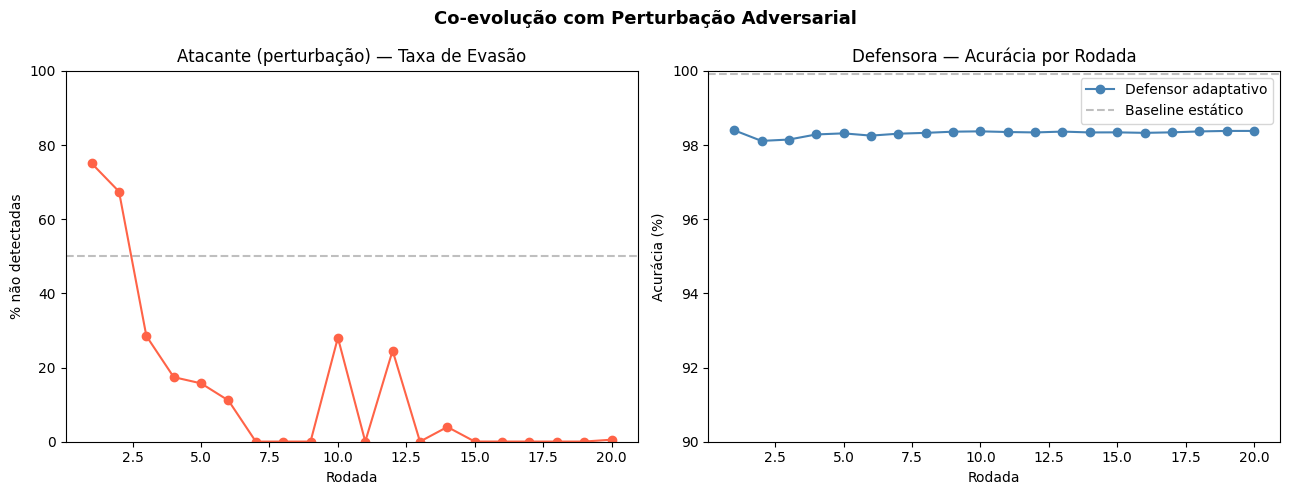
| Rodada | Taxa de Evasão | Acurácia Defensor |
|---|---|---|
| 1 | 75.1% | 98.40% |
| 2 | 67.4% | 98.11% |
| 3 | 28.5% | 98.15% |
| 7 | 0.0% | 98.31% |
| 10 | 28.0% | 98.37% |
| 20 | 0.5% | 98.38% |
O que aconteceu aqui é exatamente o que a pesquisa propõe. Três conclusões que acho relevantes:
1. Um defensor "perfeito" é vulnerável. 99.91% de acurácia num dataset estático não significa robustez a ataques que evoluem. Na rodada 1, 75% dos ataques perturbados passaram sem ser detectados.
2. O ciclo adversarial força adaptação real. O defensor não estava preparado para ataques perturbados — mas aprendeu a lidar com eles ao longo das rodadas sem precisar de dados rotulados manualmente. Nas rodadas 10 e 12 o atacante tentou "ressurgir" (28% e 24% de evasão), mas o defensor suprimiu rapidamente.
3. Existe um trade-off honesto. O defensor adaptativo ficou em ~98.3% de acurácia, abaixo dos 99.91% do baseline estático. Ele "pagou um preço" para ser mais robusto a ataques que evoluem. Esse resultado é importante — mostra que robustez adversarial tem custo, e ignorar isso seria desonesto.
O que vem por aí
Esse experimento foi a primeira implementação, feita para validar o conceito central da IC. Ainda tem muito pela frente:
- Ajustar hiperparâmetros e arquiteturas dos dois modelos
- Comparar com outros tipos de ataque além de DDoS
- Implementar métricas mais sofisticadas de realismo das amostras geradas
- Discutir formalmente o problema do equilíbrio trivial entre atacante e defensor
O objetivo final é ter um framework modular que sirva como base para estudos futuros (e quem sabe um artigo científico saindo disso).
Referências
-
Notebook no Google Colab: https://colab.research.google.com/drive/1SbbZEeh1o0_U7LG3suet0-27QV8WIV7k?usp=sharing (aviso: o notebook ainda não está organizado — tem células de teste, versões anteriores e comentários de debug. Use como referência, não como tutorial limpo)
-
Survey principal utilizado: Alauthman et al. (2026). Generative Adversarial Networks for Intrusion Detection Systems: A Comprehensive Survey of Applications, Challenges, and Research Directions. Arabian Journal for Science and Engineering. https://link.springer.com/article/10.1007/s13369-026-11103-6
-
Dataset utilizado: https://www.kaggle.com/datasets/dhoogla/cicids2017?resource=download&select=DDoS-Friday-no-metadata.parquet